-
Disentangled Representation Learning GAN for Pose-Invariant Face Recognition카테고리 없음 2019. 7. 7. 20:56
1. Introduction
포즈 변화에 상관없이 얼굴을 인식(face recognition)하는 것은 중요한 과제이다.
이 논문의 저자는 이에 대한 새로운 framework를 제시하였다.
- simultaneously learn pose-invariant identity representation and synthesize faces with arbitrary poses.

DRGAN의 generator(G)는 encoder-decoder 구조로 되어 있다.
encoder부분인 G(ENC)의 인풋은 다양한 포즈의 얼굴 이미지이고, decoder의 아웃풋은 target pose로 합성된 얼굴 이미지이다.
G는 face rotator로서 역할을 하고, D는 실제 이미지와 합성 이미지를 구분하는 것 뿐만아니라, 얼굴의 포즈와 정체성을 예측할 수 있도록 학습된다. 추가적이 classification을 통해서 D는 회전된 얼굴이 input real face와 동일한 indentity를 가지도록 노력한다. 이는 G에 두 가지 영향을 미친다.
1) The rotated face looks more like the input subject in terms of identity.
2) The learnt representation is more inclusive or generative for synthesizing an identity-preserving face.
DRGAN의 generator는 face image와 pose code c와 random noise vector z를 input으로 받는다. 특히, generator의 encoder부분은 input image로부터 feature representation을 mapping하는 것을 학습한다. 그런 다음 그 학습된 표현을 pose code와 noise vector를 연결하여 얼굴 회전을 위해 generator의 decoder부분에 넣습니다. noise는 indentity나 pose 이외에 얼굴 생김새(appearance)의 변화를 model화 한다.
DR-GAN can learn a disentangled identity rep- resentation that is exclusive or invariant to pose and other variations, which is ideal for PIFR when achievable
encoder of generator : input으로 여러 개의 사진을 받음. (training 동안 다양한 갯수의 사진을 input으로 받음). 그리고, identity representation을 만들고, 각 이미지의 coefficient를 만듬. 이 학습된 coefficient를 사용해서 하나의 representation으로 합침.
decoder of generator : 이 representation과 pose code를 사용해서 특정한 포즈의 얼굴을 합성함.
1) We propose DR-GAN via an encoder-decoder structured generator that can frontalize or rotate a face with an arbitrary pose, even the extreme profile.
2) Our representation learning is explicitly disentangled from the pose variation through the pose code in G and the pose estimation in D.
3) We propose a novel scheme to adaptively fuse multiple faces to a single representation based on the learnt coefficients.
3.2. Single-Image DR-GAN
1) face image를 위한 identity representation을 encoder-decoder 구조로 학습하는데, indentity representation은 encoder의 아웃풋이고, decoder의 인풋이다. identity representation은 같은 subject의 다양한 얼굴을 합성하기 위한 decoder의 인풋이므로 generative representation이라고 함.
2) 보통 얼굴인식을 할 때는 face apperance에 distractive한 변화가 있다. 그러므로, encoder(identity representation)에 의해서 학습되는 이 표현은 distractive side variation을 포함한다. (예를 들어서, encoder은 같은 subject에 0도냐 90도냐에 따라 다른 identity representation을 만들어낸다.) 이 문제를 해결하기 위해 semi0supervise GAN과 비슷하게 class label을 추가하였다. 포즈와 조명과 같은 side information을 추가함으로써 discriminative(구별을 나타내는) representation을 학습하는데 도움을 줄 수 있게 하였다.
3.2.1. Problem Formulation
Given a face image x with label y =

yd는 identity를 위한 label이고, yp는 pose를 위한 label이다.
objective of our learning problem : 1) RIFR을 위한 pose 불변의 identity를 학습하는 것.
2) yd와 같은 idntity를 가지지만 pose code c 에의해 지정된 pose의 얼굴 이미지를 합성하는 것.
D=


위의 식은 identity classification을 위한 식이다. Nd는 training set의 subject의 total number이고 추가적인 dimension은 fake class를 위한 것이다.
(N의 d승을 Nd라고 표현)

위의 식은 pose classification을 위한 식이다. Np는 discrete poses의 total number이다.
synthetic face image form the generator = G(x,c,z)
D는 이것을 가짜라고 구분하기를 시도한다.
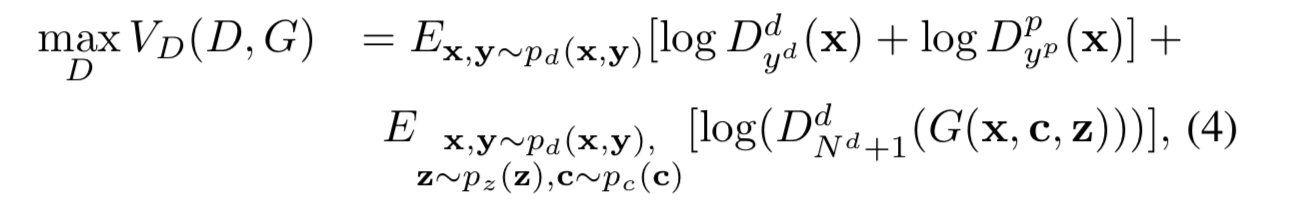
Eqn4. The first term is to maximize the probability of x being classified to the true identity and pose. The second term is to maxi- mize the probability of xˆ being classified as a fake class. Generator의 목표는 xˆ를 input x의 identity와 target pose로 분류하여 D를 속이는 것이다.

Eqn5 D가 실제 이미지와 가짜 이미지를 구별하고 포즈를 분류하는데 더 강력할 경우, G는 세가지 이점을 사용하여 target pose와 함께 identity-preserving face를 합성하게 됨.
1) 학습된 표현(learnt representation) f(x) (=identity representation)는 좀더 discriminative identity를 보존.
2) D의 pose classification은 회전된 얼굴의 포즈를 좀 더 정확하도록 가이드해줌.
3) generator의 decoder의 분리된 pose code와 함께, generator의 encoder부분은 f(x)로 부터 disentangle한 pose variation을 학습하게 함. f(x)는 가능한한 많은 identity information을 encode해야하고, 적은 pose information을 encode해야 함.
3.2.2 Network Structure

The network structure of DR-GAN. Blue texts represent extra elements to learn the coefficient w in multi-image DR-GAN. CASIA-Net을 generator의 encoder와 decoder에 채택하여 각 convolution layer 다음에 batch normalization과 exponential linear unit이 적용됨. identity classification (Nd+1) 와 pose classification(Np)을 위한 softmax loss 가진 fully connected layer를 추가함으로써 D는 Eq4을 최적화하도록 학습한다.
identity representation(320차원)은 DRGAN에서 AvgPool의 아웃풋이다. 이 identity representation은 pose code c와 random noise z와 concatenate된다. 연속된 fractionally-strided convolution (FConv)은 (320 + N p + N z )-dim concatenated vector를 합성된 이미지 xˆ = G(x, c, z)로 transform한다. 이 때 합성된 이미지는 x(input image)와 동일한 사이즈이다. x가 D에 fed되고 gradient가 G를 update하기 위해 back-propagate하기 할 때, G는 Eq5를 최적화하도록 학습한다.
3.3 Multi-Image DR-GAN
Multi-Image DR-GAN은 single-image DR-GAN과 같은 D를 가지고 있지만, 다른 G를 가지고 있다.

CVPR2017_Face_Frontalization.pdf Generator in multi-image DR-GAN. From an image set of a subject, we can fuse the features to a single representation via dynamically learnt coefficients and synthesize images in any pose. f(x)를 extracting하는 것 이외에도, generator의 encoder는 각 이미지의 confident coefficient w를 구한다. 이것은 learnt representation의 quality를 예측함. n개의 input image와 함께, fused representation은 모든 representation의 weighted average이다.

Eqn6 fused representation은 c와 z와 concatenate되고, generator의 decoder로 새로운 이미지를 만들기 위해서 fed됨. 이것은 모든 input image와 같은 identity를 가지고 있음. 그러므로 coefficient wi은 더 높은 quality를 가진 이미지를 fused representation에 더 높은 기여를 하게 만들어 줌.

2n+1 term을 가지고 있음. 여기서 quality는 PIFR 성능의 지표로 볼 수 있음. 낮은 수준의 영상 화질이 아니라.
모든 generator의 encoder는 같은 parameter를 공유함. Fig.2(d)가 training을 위해 사용되는 반변에 testing을 위한 network는 간단하다. 오직 encoder of generator만 representation을 추출하기 위해 사용되고, decoder of generator과 encoder of generator이 face rotation을 위해 사용됨.
multi-image DR-GAN은 오직 single-image DR-GAN으로부터 조금의 변화를 하였음.
구체적으로는 G의 encoder 마지막 부분에 계수 w를 추정하기 위해 AvgPool 전에 layer에 convolution channel을 하나 더 추가하였다.
Signmoid activation을 더함으로써 w를 [0,1]로 한정하였음.
불필요하지만, subject당 input image의 수를 n개로 유지하였다. 이미지 sampling의 편리함과 network training을 위해서.
입력 이미지 수의 변화를 모방하기 위해 우리는 간단하지만, 효과적인 트릭을 사용함. -> 계수 w에 대한 dropout적용.
따라서, 훈련동안 network는 1부터 n까지의 다양한 input을 취합니다.